https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf https://zhuanlan.zhihu.com/p/423565251
介绍
lsm 树读写放大显著。
机械硬盘的连续读写性能比随机读写慢100倍,因此 lsm 树的合并后一起顺序写入的方法更适合机械硬盘。
对于固态硬盘,采用传统的 lsm 树会降低吞吐,增加写负载,导致固态硬盘性能无法充分发挥。这是因为:
- 固态硬盘的连续读写速度和随机读写速度没有机械硬盘那么差别大。因此 lsm 优化的批量连续写入可能会不必要的带宽浪费。
- 固态硬盘有很大程度的内部并行性,lsm 需要小心设计以驾驭其并行性
- 固态硬盘重复写入会导致设备损耗,lsm 带来的写放大会加速设备老化
针对这些问题,wisckey 基于 lsm 树,将键与值分离以减少读写放大, 利用固态硬盘的顺序读写和随机读写的性能表现而进行优化。这样能减少排序时不必要的值移动,减少 lsm 树大小。
但也有一些挑战:
- 范围查询。由于后台值不是排序的,范围查询会很慢。用固态硬盘内部并行性解决。
- 需要垃圾回收来清理过期的值。提出了一个只涉及顺序IO,对前台影响小的垃圾回收器。
- 分离键和值会导致崩溃一致性的挑战。利用了一个文件系统的特性,在崩溃时追加不会增加垃圾。
背景
由于固态硬盘独特的擦除-写循环和昂贵的垃圾回收机制,避免随机写对于固态硬盘中也是有意义的。但是,相比于机械硬盘,固态硬盘的随机读写和连续读写性能差距并没有那么大。在某些场景下,固态硬盘的随机读写性能可以媲美连续读写。
因此提出的 wisckey 有以下特点:
- Key Value 分离,将键放在 lsm 树里面,Value 放在分离开的 Value log 里面
- 为了加速对乱序 Value 的查询,利用了固态硬盘的并行随机读特点
- 使用独有的崩溃一致性和垃圾回收技术来有效地管理 Value log
- 通过在不牺牲一致性的情况下删除 lsm 树日志来优化性能,从而减少了小型写操作带来的系统调用开销。
键值分离
lsm 树最大开销就是不断排序的压缩环节,我们观察到,压缩排序的时候,只需要排序键,而不用排序值。因此在 wisckey 中,与键一起在 lsm 树中存放的只有值的位置,而值被放在其他对固态硬盘更友好的地方。这样能大大减小 lsm 树大小,进而显著地减小写放大。
wisckey 的架构如图所示:
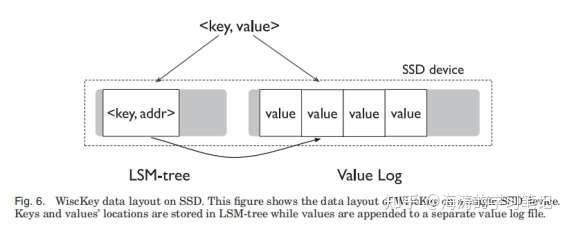
插入键值对,值会被 append 到 vLog 中,键及值的地址以 <vLog-offset, value-size> 的形式插入到 lsm 树中。删除键,只需要将键从 lsm 树中移除,不需要修改 vLog, 而 vLog 中被删除的值之后会被垃圾回收。所有在 vLog 里面有对应键在 lsm 树里面的都是有效值,没有对应键的则为无效值。
并行范围查找
由于键和值在 wisckey 中是分开存储的,范围查询需要随机读取。固态硬盘上单个线程的随机读性能低于顺序读性能。然而,如果使用并行随机读,则可以充分利用固态硬盘内部并行性,获得与顺序读相当的性能。
因此如果用户请求连续的键值对序列,wisckey 会从 lsm 树中顺序地读取许多后续键。从 lsm 树检索到的相应值的地址被插入到队列中,多个线程同时从 vLog 中读取这些值。
垃圾回收
由于 wisckey 不会压缩值,所以需要一个垃圾回收机制来回收在 vLog 中被删除的值。
一种简单的办法就是扫描 lsm 树,找到所有有效值,然后将 vLog 中没有 lsm 对应键的值给回收。但是这样开销过大,且只适用于离线的垃圾回收。
wisckey 设计的轻量在线垃圾回收器,在 vLog 中储存值,还储存了值的键的位置<key size, value size, key, value>。

vLog 一头是 head,新值会在这里 append。另一头 tail,是垃圾回收的起点。垃圾回收时,wisckey 会从 tail 读取一个键值对,然后在 lsm 中查询该值是否有效,有效则 append 到 head,最后更新 tail。
为避免垃圾回收时因崩溃而导致的数据丢失,wisckey 在 vLog 附加有效值后,会将新值的地址以及当前尾部,以同步的方式保存在 lsm 树中,最后 vLog 中的空闲空间才被回收。
崩溃一致
系统崩溃时,lsm 树能够保证插入键值对的原子性和顺序性。但 wisckey 键值分离的结构想要保证崩溃一致就比较复杂。不过借助现代文件系统(如 ext4、btrfs 和 xfs)还是能够提供和 lsm 相同的崩溃保证。这是因为现代文件系统有个性质:如果崩溃后 vlog 中的值 X 丢失了,那么所有在 X 后续插入的值都会丢失。由此保证顺序性。
如果崩溃导致在 lsm 找不到键,则值会被当成无效值被垃圾回收。如果找到了对应的键,需要检查从 lsm 获取的值地址是否在 vlog的有效范围内,以及检查从 vlog 找到值对应的键与查询的键是否一致。如果检查失败,则 lsm 删除该键,并通知用户该键不存在。由此保证原子性。出现这种情况应该是没有使用同步,如果在每次写完 vlog 后,调用 fsync 再写入 lsm,应该就不会有这种问题
这个前提建立在于 WiscKey 通过一个 Write Buffer 批量提交 Value Log(下面有详细介绍),所以才会出现 Key 写入成功后 Value 丢失的场景,用户也可以通过设置同步写入,这样在刷新 Value Log 之后,才会将 Key 写入 LSM-Tree 中。
优化
vlog 写缓冲区
频繁插入小容量写请求会显著增加开销,为此,wisckey 会在用户空间缓冲区中缓冲值,并且只在缓冲区大小超过阈值或用户请求同步插入时才刷新缓冲区。
这样查找数据需要先搜索 vlog 缓冲区,再到 vlog 中搜索。这种机制可能导致崩溃丢失缓冲区数据。怎么解决?
优化 lsm 的 log
由于 vlog 已经保存了键值对,因此我们可以通过扫描 vlog 来恢复 lsm 树(应该指的是恢复 lsm 中未落盘的数据),这样就不需要 log 文件。扫描整个 vlog 开销比较大,wisckey 会在 lsm 中记录 vlog 的 head,恢复时从该 head 开始,往新插入值的方向扫描。
既然能恢复,为啥前面说找不到键,则值会被当成无效值被垃圾回收?
实现
为了有效地回收 vlog 的空闲空间,使用了现代文件系统的穿孔功能(fallocate)。在文件上穿孔可以释放对应分配的物理空间,并允许 wisckey 弹性地使用存储空间。现代文件系统上的最大文件大小足以让 wisckey 运行很长一段时间,而不需要回退到文件的开头,如果有必要,可以将 vlog 简单地调整为循环日志。