In Search of an Understandable Consensus Algorithm
17 Apr 2022 | distributed system, paper
介绍
相比Paxos,Raft的设计目标是容易理解。为此,它将一致性算法分解成领导人选举、日志复制、安全性和成员变更几个部分,同时也通过减少状态机状态的数量来简化需要考虑的状态空间
同时Raft有一些独特的地方:
- 日志只从领导人发送给其他的服务器
- 选举的心跳机制上增加一个随机计时器
- 集群在成员变换的时候依然可以继续工作。
复制状态机
复制状态机通常都是基于复制日志实现的,只要日志都按照相同的顺序包含相同的指令,那么每个状态机执行完日志的指令都会达到同样的状态。而如何保证复制日志相同就是一致性算法的工作。
一致性算法通常含有以下特性:
- 在非拜占庭错误情况下,包括网络延迟、分区、丢包、冗余和乱序等错误都可以保证正确
- 集群中只要有大多数的机器可运行并且能够相互通信、和客户端通信,就可以保证可用
- 不依赖时序来保证一致性
- 少部分比较慢的节点不会影响系统整体的性能
Raft一致性算法
Raft通过选举一个领导人,通过领导人来管理复制日志来实现一致性。领导人从客户端接受日志,把日志复制到其他服务器,告诉其他服务器什么时候可以应用日志到状态机中。如果领导人故障或与其他服务器失去连接,会选举新的领导人。
通过这种方式,Raft将一致性问题分解为三个独立的子问题:领导人选举、日志复制(要求其他节点的日志和领导人的一致)和安全性(就是要其他服务器节点之间应用的内容要一致)
算法保证以下特性:
- 一个任期最多只有一个领导人
- 领导人只会增加自己的日志,不会删除或覆盖
- 如果两个日志在某一相同索引位置日志条目的任期号相同,那么我们就认为这两个日志从头到该索引位置之间的内容完全一致
- 如果某个日志条目在某个任期号中已经被提交,那么这个条目必然出现在更大任期号的所有领导人中
- 如果某一服务器已将给定索引位置的日志条目应用至其状态机中,则其他任何服务器在该索引位置不会应用不同的日志条目
Raft基础
服务器节点的状态有三种:
- 领导人处理所有的客户端请求,如果一个客户端和跟随者联系,那么跟随者会把请求重定向给领导人
- 跟随者只是简单的响应来自领导人或者候选人的请求
- 候选人用来选举新领导人
状态变化图:
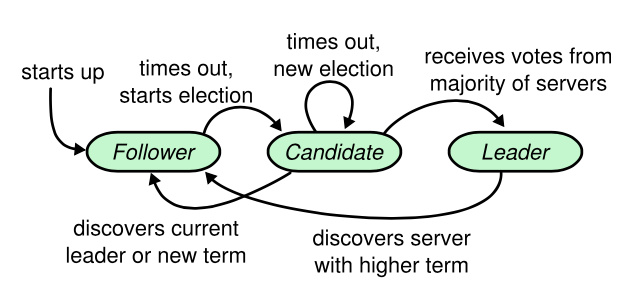
有时候选举会失败,那么这个任期就会没有领导人而结束,然后重新进行选举。
不同的服务器节点可能多次观察到任期之间的转换,但在某些情况下,一个节点也可能观察不到任何一次选举或者整个任期全程。比如网络分区的情况,7个节点被分成2(包含领导人)和5?。
任期在Raft算法中充当逻辑时钟的作用,通过比较任期的大小来决定接下来的操作。
节点间通信使用远程过程调用(RPCs),一共有三种,只要前两种就能实现基本的一致性算法,第三种是为了性能而引入的:
- 请求投票(RequestVote):由候选人在选举期间发起
- 附加条目(AppendEntries):由领导人发起,用来复制日志和提供心跳
- 安装快照(InstallSnapshot):领导人发送快照给落后的跟随者
领导人选举
领导人会定期向所有跟随者发送心跳包。
跟随者只要在一段随机时间内接收到从领导人或者候选人处发来的有效的RPCs,就一直保持状态,否则会发起选举。
选举时,跟随者会增加当前任期号并转为候选人状态,等待一段随机的时间后并行地向其他节点发送请求投票的RPCs,直到:赢得选举、其他节点成为领导人、没有人获胜:
- 候选人如果从大多数服务器节点获得了针对同一个任期号的选票,就赢得选举并转为领导人。每个服务器对一个任期号,按照先来先到的原则投出一张选票。如果候选人发送的请求投票RPCs,有少数没有回应,应该一直等待吗?如果多数没有回应呢?
- 候选人可能会收到声称是领导人的心跳包,如果该心跳包的任期号不小于当前任期号,则承认该领导人合法并转为跟随者。否则继续保持候选人。如果一个跟随者错失一个心跳包,岂不是会发起选举。网络不好的情况下,整个系统会不会一直发生选举
- 如果有多个候选人且没人获胜,那么每个候选人都会增加任期号并开始新选举。
日志复制
当客户端发送请求给领导人,领导人会并行地发起附加条目RPCs给跟随者,当日志都被安全地复制,领导人就会把这个请求应用到它的状态机上并返回结果给客户端。
如果跟随者崩溃或者运行缓慢,再或者网络丢包,领导人会不断的重复尝试(尽管已经回复了客户端)直到所有的跟随者都最终存储了所有的日志条目。
已提交的日志都是持久化的并且会被所有可用的状态机执行。当领导人将日志复制到大多数服务器上时,日志及之前的所有日志都会被提交。领导人会记录被提交日志的索引,并将其附在附加条目RPCs中(包括心跳包)。这样跟随者知道一条日志条目已经被提交,就会将日志应用到本地的状态机中。如果日志被复制到大多数机器上,领导人把日志应用到状态机后掉线。新领导人是日志未被复制的机器,会怎么样?
领导人在发送附加条目RPCs时,也会附上前一条日志条目的索引位置和任期号。跟随者会在收到附加条目做一致性检查:如果在日志中找不到相同索引位置和任期号的条目,就会拒绝接收。当附加日志RPC成功返回,领导人就知道跟随者的日志一定是和自己相同的了。如果顺序发送的两条日志按照相反顺序到达跟随者,会怎样?
面对日志不一致的情况,领导人强制跟随者直接复制自己的日志进行覆盖。因此领导人需要确定最后两者达成一致的地方,然后发送从那之后的日志给跟随者。
领导人针对每一个跟随者维护了一个nextIndex,这表示下一个需要发送给跟随者的日志条目的索引地址。当一个领导人刚获得权力的时候,他初始化所有的nextIndex值为自己的最后一条日志的 index加1。如果一个跟随者的日志和领导人不一致,那么在下一次的附加日志RPC时的一致性检查就会失败。在被跟随者拒绝之后,领导人就会减小nextIndex值并进行重试。最终nextIndex会在某个位置使得领导人和跟随者的日志达成一致。当这种情况发生,附加日志RPC就会成功,这时就会把跟随者冲突的日志条目全部删除并且加上领导人的日志。
这里有个优化的地方,就是当附加日志RPC的请求被拒绝的时候,跟随者可以返回冲突条目的任期号和该任期号对应的最小索引地址。这样领导人可以减小nextIndex一次性越过该冲突任期的所有日志条目。
安全性
选举限制 请求投票RPC中包含了候选人的日志信息,投票人会拒绝掉那些日志没有自己新(任期号不同,那么任期号大的日志更加新,否则索引值大的新)的投票请求,这样可以保证在选举的时候新的领导人拥有所有之前任期中已经提交的日志条目。
提交之前任期内的日志条目 有了选举限制,领导人知道当前任期内的日志,如果被复制到大多数节点,那么是可以被提交的。但是领导人不能断定之前任期的日志可以被提交。这是因为之前任期的日志有可能会被未来的领导人覆盖掉:
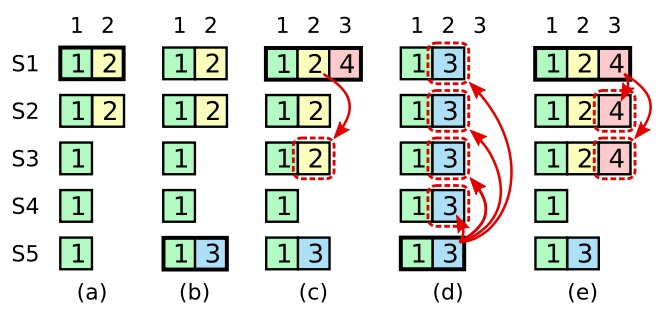
如场景c,当前任期是4,领导者知道任期2的日志已经被复制到大多数节点,但是也不能就确定任期2的日志已可以被提交,因为任期2、4的日志在场景d下被覆盖了。
只有当前任期的日志被复制到大多数节点,如场景e,此时即使S1掉线,S5节点也不会满足称为领导者的条件。因此任期4的日志可以安全地被提交,再加上日志匹配特性,之前的日志(如任期2)也会被提交。
跟随者和候选人崩溃
不停重试。Raft的RPCs是幂等的,跟随者如果收到已经包含的附加日志请求,会直接忽略。
时间和可用性
Raft需要满足下面的时间要求: 广播时间(broadcastTime) « 选举超时时间(electionTimeout) « 平均故障间隔时间(MTBF)
集群成员变化
在实践中,集群的配置(加入到一致性算法的服务器集合)是可能改变的,这种变化是不安全的。因此Raft使用两阶段方法来进行配置更改:第一个阶段是老配置和新配置的结合,称为共同一致;第二个阶段是提交共同一致,系统切换到新配置。
共同一致可以让集群在配置转换的过程中依然响应客户端的请求,它有以下特点:
- 日志条目被复制给集群中新、老配置的所有服务器
- 新、旧配置的服务器都可以成为领导人
- 达成一致需要分别在两种配置上获得大多数的支持
集群配置在复制日志中以专门的日志来存储和通信。服务器只要收到新的配置日志,就会使用新配置,无论该日志是否被提交。
首先客户端向领导人发送更改配置的请求,领导人就会向集群中新老配置的所有服务器复制C-old,new日志,这个日志只有在新老配置中都超过半数节点复制成功,才能被提交。一旦C-old,new被提交,领导人完全特性保证了只有拥有C-old,new日志的服务器才有可能被选举为领导人。
接着领导人创建一条C-new配置的日志并复制给集群,跟随者收到C-new日志且已经收到C-old,new,会马上切换到新配置。当C-new被复制到新配置的大多数节点,C-new便可以提交,此时关闭老配置的服务器就是安全的。
此外还有一些要点:
- 新服务器可能会发生追赶的情况,这时还不能提交新的日志。为避免这种短暂的不可用,规定追赶阶段的节点没有投票权
- 领导人可能不是新配置的一员。这意味着有这样的一段时间,领导人管理着集群,但是不包括他自己,直到C-new被提交发生了领导人过渡
- 当集群转为新配置,老配置的服务器不再收到心跳,会发生新选举。新选举后也是收不到心跳,会重复发起选举。为避免这种情况,当服务器在当前最小选举超时时间(注意不是选举超时时间)内收到一个请求投票RPC,他不会更新当前的任期号或者投出选票
日志压缩
在实际中,日志会不断地增长,Raft采用快照技术对日志进行压缩。每个服务器独立地为已经被提交的日志创建快照。
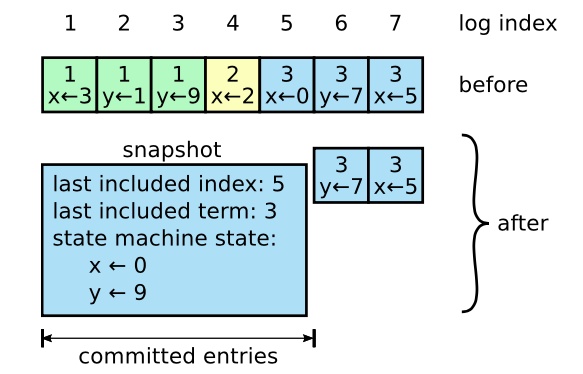
领导人通过发送快照(安装快照RPC)让跟随者更新到最新的状态。如果跟随者收到的快照比已有日志新,则丢弃全部日志,使用快照替代。如果收到的快照比已有日志旧,则被快照包含的日志全部删除,快照后的日志保留。
影响快照的性能有两点:什么时候创建快照、写入快照不要影响正常操作。可以通过设置阈值和写时复制技术来解决上面两个问题。
客户端交互
如果客户端交互的服务器不是领导人,那么服务器会拒绝客户端的请求并且提供最近接收到的领导人的信息。
考虑这种情况,领导人接受客户端请求并提交日志,但是在响应客户端之前崩溃。那么客户端会和新的领导人重试这个请求,导致重复执行。为此,Raft客户端对每一条指令都赋予唯一的序列号,服务器如果发现该序列号对应的指令已执行,则直接返回结果。这需要跟踪每条指令最新的序列号和相应的响应。
只读的操作可以领导人直接处理而不需要记录日志并复制到大多数节点,但是响应客户端的服务器可能已经不是领导人了。因此不记录日志的只读,Raft额外使用了两种措施:
- 领导人在任期开始时可能不知道哪些日志是已被提交的,因此需要在任期开始时提交一个空白的日志。为啥?
- 处理只读的请求之前,和大多数节点交换心跳,来检查自己是否已经被废黜。交换心跳后,处理只读请求前,被废除呢?