最近我摸索出了给技术书籍做笔记的方法,于是也开始思考如何整理源代码阅读笔记。
2022-04-09:效果不太行,笔记有点简陋。参考这个博客,应该记录得更细致一点,不要介意贴大段代码。再附上一些值得学习的博客:youjiali、ying、rin、catkang
简介
LevelDB不是SQL数据库,没有关系模型,不支持SQL语句,不支持索引。不能多个进程同时访问数据库,同一个进程的多个线程可以同时操作。
Key
user_key 用户输入的key
InternalKey 数据库内部使用的Key,格式user_key SequenceNum Type
LookupKey 格式InternalKeyLength InternalKey
Varint32/64 对于数值小的数字,不需要4bytes、8bytes,会浪费空间。使用变长的表示方法,每7bit代表一个数,第8bit代表是否还有下一个字节。
Comparator
Comparator 抽象类,要求派生类实现比较方法、用来找到比传入实参大的值的函数:FindShortestSeparator和FindShortSuccessor。
BytewiseComparatorImpl Comparator的派生类,简单对字符串进行比较。
FindShortestSeparator(std::string* start, const Slice& limit的一个参数如果是另一个的字串,则不做处理,否则返回公共字串拼接一个字符:(*start).substr(diff_index) ++ ((*start)[diff_index]+1)
FindShortSuccessor(std::string* key)返回第一个字符+1:(*key)[i]+1
InternalKeyComparator Comparator的派生类,对InternalKey进行比较。持有用户定义的Comparator。
比较user_key部分会调用用户的Comparator,默认使用BytewiseComparatorImpl。如果user_key相等,则依次对比SequenceNum和Type,这两者越大InternalKey越小。
FindShortestSeparator和FindShortSuccessor也是调用用户的Comparator,接着加上SequenceNum和Type。
迭代器
Iterator 抽象类。允许注册清理函数RegisterCleanup,可以注册多个,在迭代器析构时调用。
IteratorWrapper 持有Iterator* iter_。提供和Iterator同样的接口,将调用转发给iter_。记录iter_的key和value,避免多次调用虚函数。
TwoLevelIterator Iterator的派生类,二级迭代器。持有指向第一层的IteratorWrapper index_iter_,由构造函数初始化,和指向第二层的IteratorWrapper data_iter_。迭代器操作都是在data_iter_上。
构造时会传入一个返回Iterator*的函数指针BlockFunction,用来获得index_iter_的value指向对应容器的第二层迭代器data_iter_。当index_iter_更新,会调用BlockFunction获得新的data_iter_
MemTable
Arena 一个简单的内存池。其中类成员char* alloc_ptr_指向当前空闲内存地址,size_t alloc_bytes_remaining_记录当前块剩余容量,vector<char*> blocks_,保存所有内存块的地址。
提供char* Allocate(size_t bytes)的接口。当bytes小于alloc_bytes_remaining_,返回alloc_ptr_。否则new新的char数组,新数组大小为4K或bytes(当bytes>1K),alloc_ptr_指向新地址。注意,旧内存块剩余的空间会浪费掉。
也提供对齐Allocate的接口,实现方式同上
SkipList 使用原子操作和模板技术实现跳表。不支持删除,不能插入重复值。使用Arena来分配新节点的内存。后趋节点数组使用柔性数组实现。上一层节点数是下一层的1/4。
未实现del操作是因为元素删除也是插入,删除某个Key的Value在 Memtable 内是作为插入一条记录实施的,但是会打上一个 Key 的删除标记,真正的删除操作是Lazy的,会在以后的 Compaction 过程中去掉这个KV。
MemTable 持有Arena和SkipList。引用计数,没有被引用时delete this。跳表节点格式为LookupKey ValueLength Value
MemTableIterator Iterator的派生类,对SkipList::Iterator进行封装
WriteBatch 将所有的操作记录到rep_,然后再通过WriteBatch::Iterate(Handler* handler)一起提交。其中每次提交都会递增序列号。
WriteBatch::rep_ :=
sequence: fixed64
count: fixed32
data: record[count]
record :=
kTypeValue varstring varstring |
kTypeDeletion varstring
varstring :=
len: varint32
data: uint8[len]
其中WriteBatch、WriteBatchInternal、Handler三者的关系可以学习一下
// include/leveldb/write_batch.h 暴露给用户的api
class WriteBatch {
public:
class Handler {
public:
virtual void Put(const Slice& key, const Slice& value) = 0;
...
};
Status Iterate(Handler* handler) const; // 将rep_中的数据通过handler提交出去
...
private:
friend class WriteBatchInternal;
};
// db/write_batch_internal.h 暴露给内部使用的api
class WriteBatchInternal {
public:
static Status InsertInto(const WriteBatch* batch, MemTable* memtable);
...
};
// db/write_batch.cc
namespace {
// 提交给MemTable的hander,同时会维护序列号,每次提交递增
class MemTableInserter : public WriteBatch::Handler { ... };
}
Status WriteBatchInternal::InsertInto(const WriteBatch* b, MemTable* memtable) {
MemTableInserter inserter;
...
return b->Iterate(&inserter);
}
Log
每32K为一个Block,Block由Record组成。格式如下:
Block := Record *
Record := Header Content
Header := Checksum Length Type
Type := kFullType | kFirstType | kMiddleType | kLastType
Type用来表明当前Record中的数据与要写入数据的关系。
Writer 提供AddRecord接口,将数据按照上述格式写入文件,文件在构造时指定
Reader 提供ReadRecord接口,按照上述格式读出文件的数据,文件在构造时指定
FilterPolicy
BloomFilterPolicy 布隆过滤器,key是user_key
InternalFilterPolicy Wrapper,处理InternalKey,转而调用布隆过滤器
SSTable
MergingIterator Iterator的派生类,用于归并排序。类成员有数组children_,数组对象是有序块的IteratorWrapper。每次调用Next(),类成员IteratorWrapper* current_访问具有最小key的块
BlockHandle 记录Block的大小和偏移值。
Table 格式如图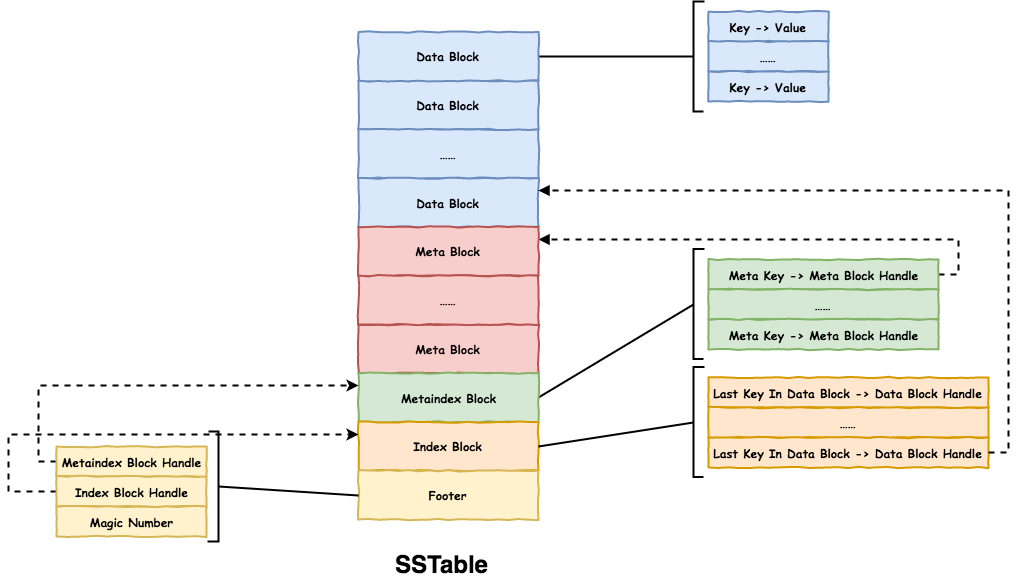
Block 格式如图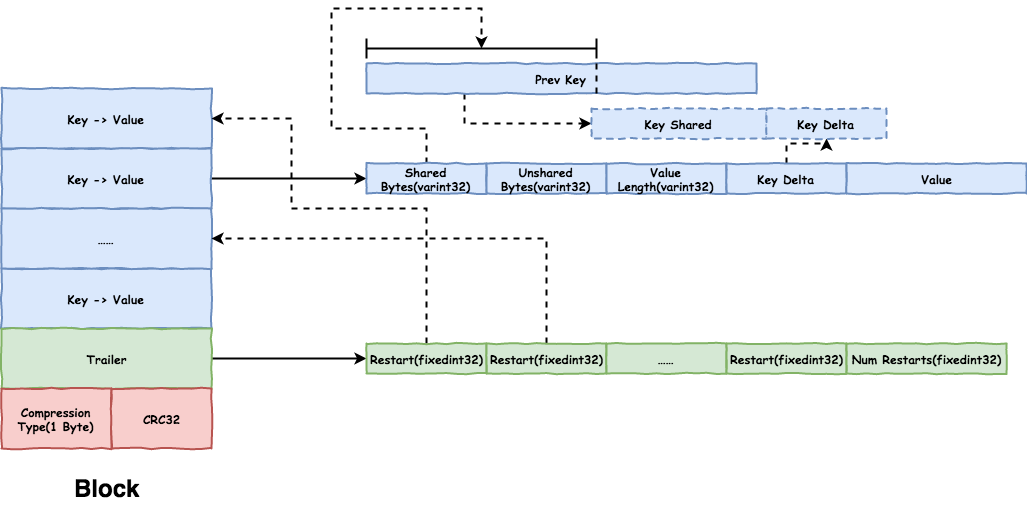 。顺序存储,因此可以二分查找。
。顺序存储,因此可以二分查找。
利用有序数组相邻Key可能有相同的前缀的特点来减少存储数据量。同时为了降低最开头数据损坏,其后的无法无法恢复的风险,还引入了重启点。
Data Block key是InternalKey
Meta Block 格式如图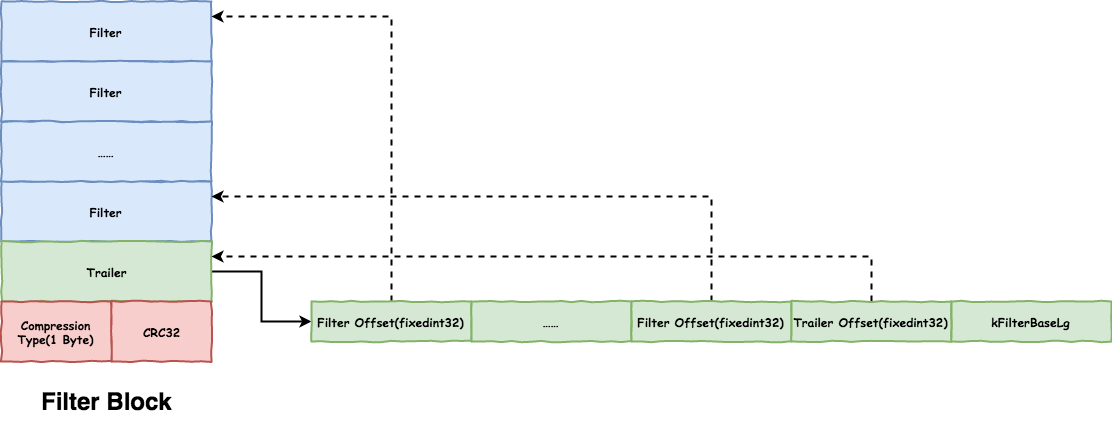
Data Block每2KB生成一个filter索引
Metaindex Block key为filter.name,Value为该Meta Block的BlockHandle
Index Block 记录Data Block位置信息,key为指向的Data Block最后一条数据的Key,Value为该Data Block的BlockHandle
Footer 解析的起点,大小固定
Cache
Cache 抽象类。
Cache::Handle Insert等操作返回的句柄
LRUHandle HandleTable和LRUCache的节点,拥有前驱后趋指针。使用柔性数组存放key。没继承Cache::Handle?
HandleTable 使用拉链法的哈希表,节点是LRUHandle
LRUCache 持有HandleTable来快速查找LRUHandle节点,以及两个LRUHandle链表 lru_、in_use_。被引用到的节点放在in_use_中,当没被引用则转移到lru_。
lru_链表采用LRU算法进行管理。如果达到上限,则调用最久未使用节点的deleter,并释放空间,这个deleter在插入该节点时定义。
ShardedLRUCache Cache的派生类,持有LRUCache数组,对key进行哈希分区到数组中,作用是减少多线程对同一个LRUCache对象的争用。接口对LRUCache进行简单封装。
版本控制
TableCache 持有ShardedLRUCache,缓存SSTable文件的句柄。ShardedLRUCache的节点以文件编号为key,{RandomAccessFile*, Table*}*为value,deleter是清理value中成员申请的内存。
当调用Get函数找到key,会使用found_key 、found_value作为实参,调用传入Get的函数指针实参handle_result
FileMetaData SSTable文件的元信息,包括文件大小,文件编号,最大最小InternalKey,引用计数(被不同Version引用)
Version 记录当前版本所有文件的信息vector<FileMetaData*> files_[config::kNumLevels]。作为VersionSet的节点,拥有前驱和后趋的节点指针。析构会修改前驱和后趋指针、减少files_中文件的引用,如果引用为零则delete
提供在当前版本所有文件进行操作的方法,如查找key、MemTable应该保存的层数等。
MemTable不一定是保存在level0,能保存的层数为0、1、2。保存到高层的条件之一是,在底层没有重叠区间。
当前为level n,推向下一层level的条件是:与level n+1不能重叠,与level n+2重叠的文件大小不能超过阈值。
保存在第0层,可能导致文件过多,压缩和查找费时。保存到太高层(3+),会导致查找太深入,要打开的文件太多。如果该范围的更新比较频繁,往高层更压缩的开销也大。
Version::LevelFileNumIterator Iterator的派生类,是Version::files_中某一层的迭代器。key()返回指向FileMetaData的最大InternalKey,value()返回该FileMetaData的文件编号和文件大小,
VersionEdit 保存相邻两个Version的差异(比如vector<pair<int, FileMetaData>> new_files_用来记录新增了哪些文件),并提供序列化反序列化VersionEdit的接口。每次压缩完成,会向manifest文件写入VersionEdit
manifest 中除了记录当前 memtable 对应的 log file 还需要记录 immutable memtable 的 log file,只有当 immutable memtable compaction 时 才可以删除对应的 log file。manifest 中记录的 sequence 并不是最新的,重启 db 时会根据 log file 恢复到最新。
manifest 在 db 打开时一直追加,不会进行清理,只有下一次打开时才会清理。若不幸 manifest 文件有所损坏或者被删除了,leveldb 也提供了修复的方式,所有的 metadata 除了 sstable 的组织结构外,都可以 通过 sstable 和 log 文件恢复,同时会将 log 转换为 sstable 并认为所有的 sstable 都处于 level-0,然后将修复后的 metadata 写入 manifest。会在打开 db 时立刻触发一次 compaction,因为 所有文件都在 level-0 所以 compaction 耗时会很久。
VersionSet 管理Version链表,记录日志序号等状态信息。提供返回Compaction的接口
重启时会根据manifest中的VersionEdit恢复并只保留最新的Version,并清理无用数据。
VersionSet::Builder 用来应用VersionEdit。调用Apply会修改VersionSet::compact_pointers_,记录VersionEdit的deleted_files_和new_files_。当调用SaveTo会在构造传入的Version的files_上加上没被删除的新文件
SnapshotList 维护双向链表,节点的值是SequenceNumber。链表支持向末尾加入节点,以及删除任意节点。
在compaction时会保留所有有可能被snapshot访问到的数据。不会持久化snapshots,重启时所有snapshots就无效
压缩
Compaction vector<FileMetaData*> inputs_[2]持有将要压缩的文件,提供一些压缩过程需要的信息
DBIter Iterator的派生类,持有MergingIterator,返回小于当前序列号的非删除user_key。与MergingIterator的差别在于,MergingIterator的粒度是InternalKey,会在user_key相同的InternalKey中遍历。DBIter每次遍历的user_key都不同。
遍历会随机抽样,检查是否执行压缩过程。如果该InternalKey出现在不同层次,则减少位于最新层次SSTable文件的计数器,当归零时触发压缩。
DBImpl 核心类,实现DB的接口,主要做压缩相关的工作。
压缩可分为以下几种:
- minor Compaction:将内存中的
memtable写入磁盘 - major Compaction:对相邻
level有重叠SSTable文件进行压缩- manual Compaction:手动触发压缩
- size Compaction:某一层的总文件大小超过阈值触发压缩
- seek Compaction:太多查询没有命中该文件,而在下一层命中时,触发压缩。查询的key在这个文件范围内,但是却不在这个文件里,每次到这里都需要多读一次磁盘,那么把这个文件往高一层合并,可以避免在当前层无效地读文件。
挑选需要压缩文件的过程,会有一个轮转机制。记录上一次被压缩文件的位置,下一次从该位置开始查找,保证每一个文件都有被合并的机会。
smallest snapshot能够访问到的及更高版本的,即保存第一个小于等于smallest snapshot的版本及更高版本即可。- 若第一个小于等于
smallest snapshot的版本是删除操作,只要高层没有这个key也可以丢弃这个版本。
TODO
- 使用raw指针和引用计数方法,要很注意对象的所有权、生命期。
- 每个模块暴露哪些内容,其他内容如何封装。
- 考虑每个模块是如何发展到如今样子的,能否给之后自己的编码提供指导。
- 测试的书写方法
- 如何实现线程安全,理清其中加锁的逻辑
- Version部分有不少回调函数的使用,可以仔细琢磨一下